更新时间:2023-01-29 来源:黑马程序员 浏览量:

前面所涉及的Pandas对象都只有一层索引结构(行索引、列索引),又称为单层索引,层次化索引可以理解为单层索引的延伸,即在一个轴方向上具有多层索引。
对于两层索引结构来说,它可以分为内层索引和外层索引。以某些省市的面积表格为例,我们来认识一下什么是层次化索引,具体如图3-6所示。
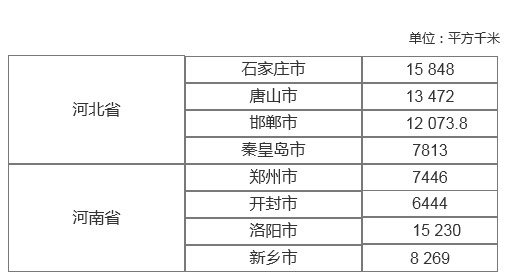
图3-6 层次化索引图示
在图3-6中,按照从左往右的顺序,位于最左边的一列是省的名称,表示外层索引,位于中间的一列是城市的名称,表示内层索引,位于最右边的一列是面积的大小,表示数据。
Series和DataFrame均可以实现层次化索引,最常见的方式是在构造方法的index参数中传入一个嵌套列表。接下来,以图3-6为例,创建具有两层索引结构的Series和DataFrame对象,具体如下:
(1)创建具有两层索引结构的Series对象,具体代码如下。
In [65]: import numpy as np import pandas as pd mulitindex_series = pd.Series([15848,13472,12073.8, 7813,7446,6444,15230,8269], index=[['河北省','河北省','河北省','河北省', '河南省','河南省','河南省','河南省'], ['石家庄市','唐山市','邯郸市','秦皇岛市', '郑州市','开封市','洛阳市','新乡市']]) mulitindex_series Out[65]: 河北省 石家庄市 15848.0 唐山市 13472.0 邯郸市 12073.8 秦皇岛市 7813.0 河南省 郑州市 7446.0 开封市 6444.0 洛阳市 15230.0 新乡市 8269.0
上述示例中,在使用构造方法创建Series对象时候,index参数接收了一个嵌套列表来设置索引的层级,其中,嵌套的第一个列表会作为外层索引,而嵌套的第二个列表会作为内层索引。
(2)创建具有两层索引结构的DataFrame对象,具体代码如下。
In [66]: import pandas as pd
from pandas import DataFrame, Series
# 占地面积为增加的列索引
mulitindex_df = DataFrame({ ‘占地面积’ :[15848, 13472, 12073.8,
7813, 7446, 6444, 15230, 8269]},
index=[['河北省','河北省','河北省','河北省',
'河南省','河南省','河南省','河南省'],
['石家庄市','唐山市','邯郸市','秦皇岛市',
'郑州市','开封市','洛阳市','新乡市']])
mulitindex_df
Out[66]:
占地面积
河北省 石家庄市 15848.0
唐山市 13472.0
邯郸市 12073.8
秦皇岛市 7813.0
河南省 郑州市 7446.0
开封市 6444.0
洛阳市 15230.0
新乡市 8269.0使用DataFrame生成层次化索引的方式与Series生成层次化索引的方式大致相同,都是对参数index进行设置。
需要注意的是,在创建层次化索引对象时,嵌套函数中两个列表的长度必须是保持一致的,否则将会出现ValueError错误。
除了使用嵌套列表的方式构造层次化索引以外,还可以通过MultiIndex类的方法构建一个层次化索引。MultiIndex类提供了3种创建层次化索引的方法,具体如下:
◆MultiIndex.from_tuples():将元组列表转换为MultiIndex。
◆MultiIndex.from_arrays():将数组列表转换为MultiIndex。
◆MultiIndex.from_product():从多个集合的笛卡儿乘积中创建一个MultiIndex。
使用上面的任一种方法,都可以返回一个MultiIndex类对象。在MultiIndex类对象中有三个比较重要的属性,分别是levels、labels和names,其中,levels表示每个级别的唯一标签,labels表示每一个索引列中每个元素在levels中对应的第几个元素,names可以设置索引等级名称。
















 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营

















.jpg)